
Más que "hay algo adelante": un asistente que nombra el mundo
¿Es suficiente saber que tienes algo enfrente, sin saber qué es? Para moverse con confianza no basta con esquivar bultos: hay que entender el entorno. Los bastones electrónicos típicos resuelven una sola cosa, detectar un obstáculo con ultrasonido y avisar con un beep. La persona sabe que hay algo, pero no sabe qué. ¿Es una pared? ¿Una persona parada? ¿Un auto? Esa diferencia importa en la calle real.
Este proyecto, inspirado en el trabajo de Engr. Shahzada Fahad (Electronic Clinic) sobre la RDK X5 de D-Robotics, da un salto cualitativo: un sistema de visión por computadora portátil que reconoce objetos en tiempo real y los dice por audio. En vez de "beep, beep, beep", la persona escucha "persona adelante", "bicicleta adelante" o "auto al frente". La promesa no es perfección, es información con sentido.
Al terminar vas a entender cómo se arma el hardware, cómo se le da voz a la placa con eSpeak, cómo el modelo decide qué objetos vale la pena anunciar (y cuáles ignorar para no saturar al usuario) y cómo extenderlo para reconocer billetes chilenos.
Por qué la RDK X5 (y no una Raspberry Pi pelada)
La gracia de la RDK X5 es que trae una NPU (Neural Processing Unit, la BPU de D-Robotics) integrada: corre el modelo de detección de objetos directo en hardware, en tiempo real, sin pedir aceleradores externos. Para hacer lo mismo con otras placas necesitarías sumar electrónica extra. Incluso con una Raspberry Pi reciente tendrías que agregarle un AI HAT aparte para alcanzar velocidad usable; en la RDK X5 la capacidad de inferencia ya viene adentro.
Esa integración es justo lo que hace viable un asistente que la persona lleva encima: menos placas, menos cables, menos consumo y una sola unidad que ve y habla al mismo tiempo.

Hardware del prototipo
- RDK X5 de D-Robotics: la cabeza del sistema, con NPU integrada.
- Cámara USB o cámara MIPI. El autor eligió la USB por flexibilidad para un wearable: vienen en muchos formatos y tamaños y son fáciles de conseguir.
- Audífonos conectados al jack de 3.5 mm de la RDK X5. La placa entrega audio sin amplificador externo.
- Fuente 5V/3A más batería 4S de iones de litio para portabilidad real.
- Carcasa wearable: bolso bandolera, mochila chica o arnés tipo cinturón sobre el pecho.
Para un USB camera puedes usar cualquier webcam estándar. La cámara MIPI usa cable flex; si la prefieres, fíjate en la orientación del conector porque entra al revés con facilidad.

Para la energía, el autor armó una fuente switching de 5V/3A alimentada por un pack 4S de litio. Esa combinación entrega los amperios que pide la placa bajo carga de inferencia y deja todo el conjunto independiente del enchufe.

Para una versión "de escritorio" antes de pasar a wearable: cualquier cámara USB, un monitor HDMI, teclado y mouse para el setup, y unos parlantes USB. Esos parlantes se alimentan desde el propio puerto USB de la RDK X5, sin fuente aparte. La placa funciona como una mini PC con salida HDMI.
Dale voz a la placa con eSpeak
Antes de tocar visión, hay que confirmar que la RDK X5 puede hablar. Para eso se instala eSpeak, un motor de texto a voz liviano que corre offline (clave en un dispositivo de asistencia: no puede depender de internet). Abre una terminal en el escritorio y corre:
sudo apt update
sudo apt install espeak
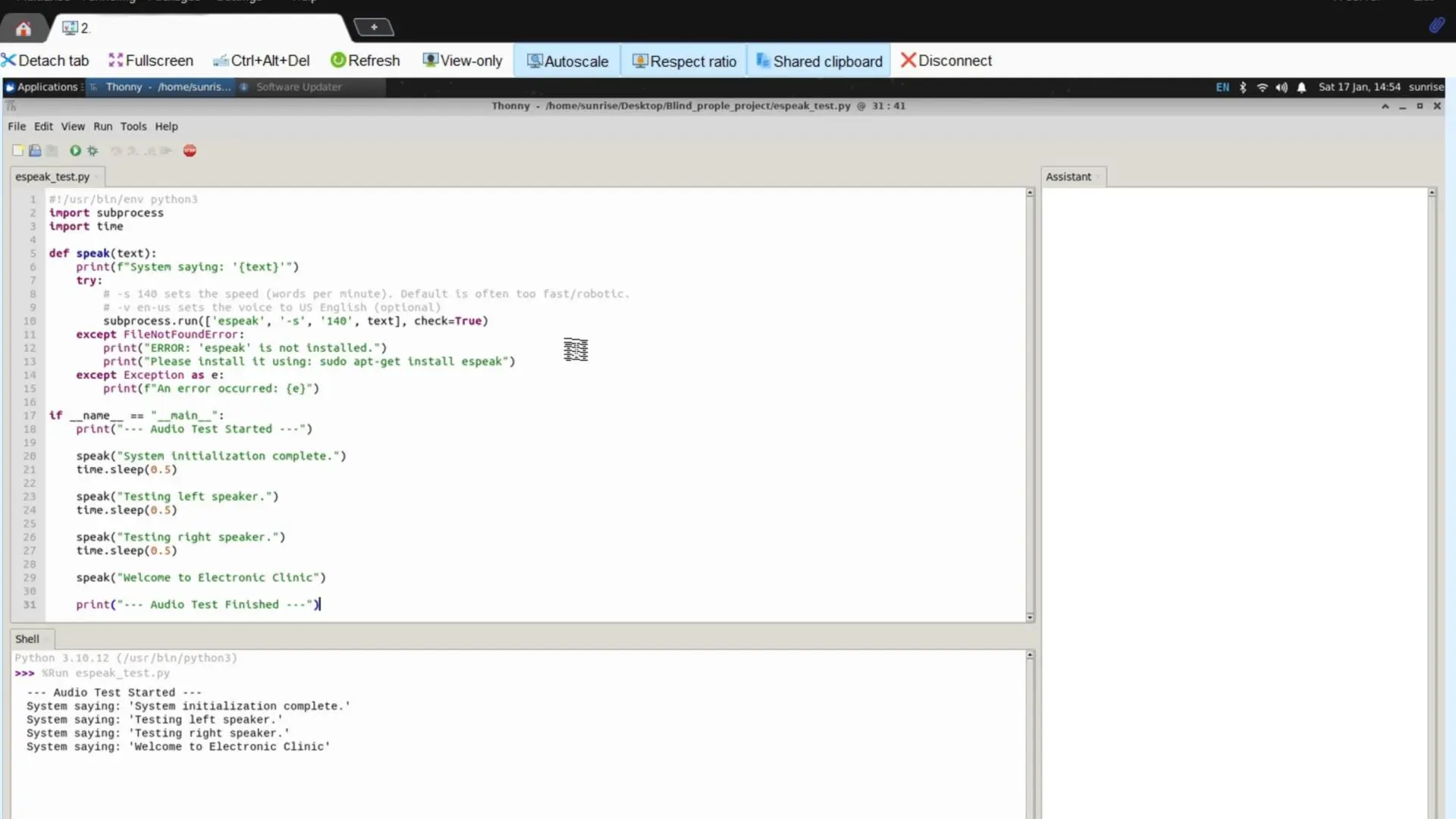
Test rápido de TTS
Con eSpeak instalado, valida que el audio sale por los audífonos o parlantes con un script mínimo. Manda unas frases con pausas para escuchar cada una clara:
#!/usr/bin/env python3
import subprocess
import time
def speak(text):
print(f"System saying: '{text}'")
try:
# -s 140 fija la velocidad (palabras por minuto). El default suele sonar muy rápido.
# -v en-us cambia la voz a inglés de EE.UU. (opcional)
subprocess.run(['espeak', '-s', '140', text], check=True)
except FileNotFoundError:
print("ERROR: 'espeak' no está instalado.")
print("Instálalo con: sudo apt-get install espeak")
except Exception as e:
print(f"Ocurrió un error: {e}")
if __name__ == "__main__":
print("--- Audio Test Started ---")
speak("System initialization complete.")
time.sleep(0.5)
speak("Testing left speaker.")
time.sleep(0.5)
speak("Testing right speaker.")
time.sleep(0.5)
speak("Welcome to Electronic Clinic")
print("--- Audio Test Finished ---")
La voz suena algo robótica, pero se entiende. Para un asistente lo que importa es la claridad, no que parezca humana. Si no escuchas nada, revisa el ruteo de audio: corre amixer scontrols para ver los controles y amixer sset 'Master' 100% para subir el volumen al máximo.
Qué objetos anunciar (y cuáles ignorar)
El loop es simple de explicar: la cámara mira al frente, el modelo YOLO detecta objetos y luego una capa de lógica decide cuáles importan. El sistema no anuncia todo: se queda con una lista corta de objetos relevantes para caminar (personas, vehículos, señales de tránsito y animales).
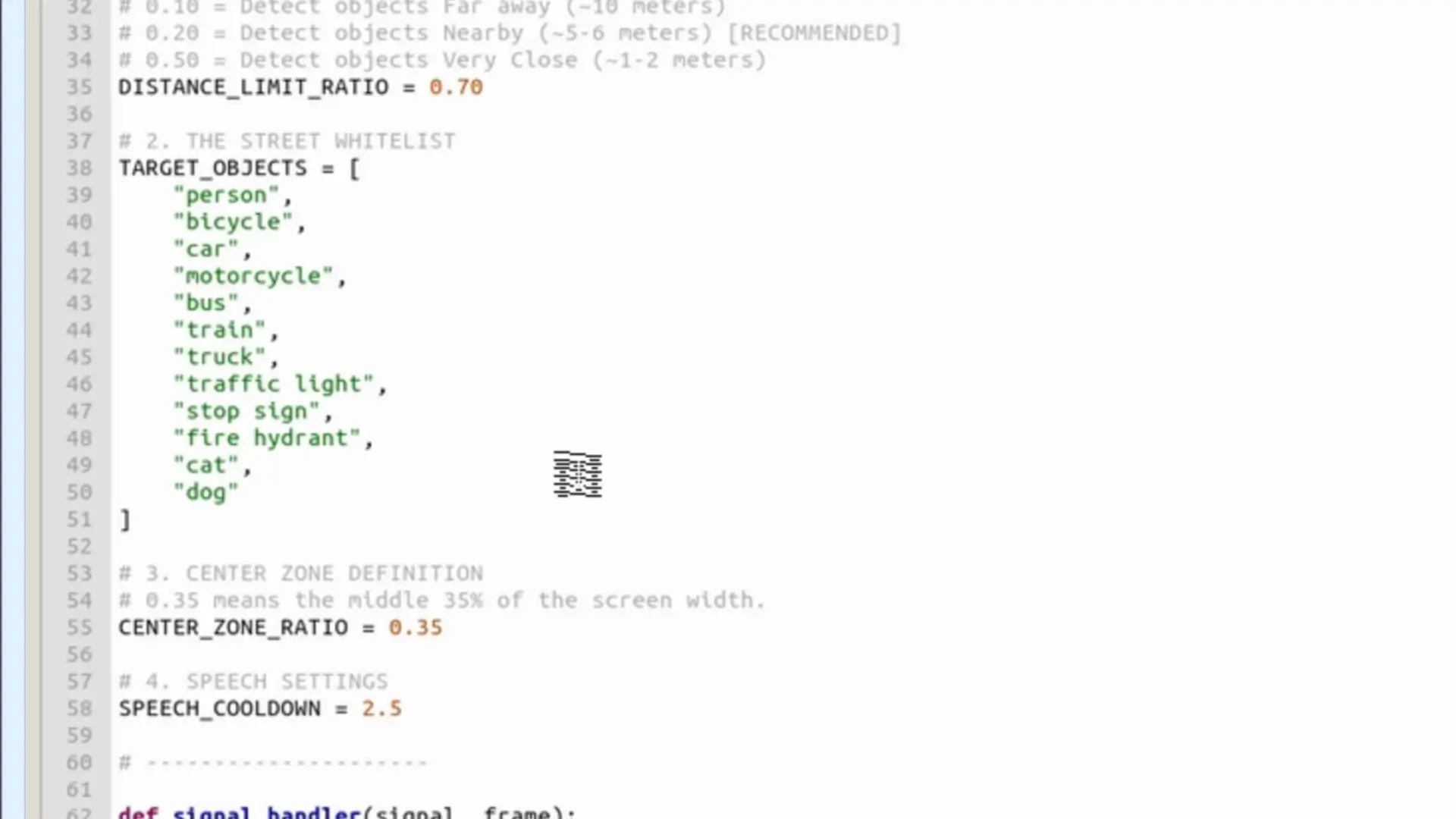
# 2. LISTA BLANCA DE OBJETOS
TARGET_OBJECTS = [
"person", "bicycle", "car", "motorcycle",
"bus", "train", "truck", "traffic light",
"stop sign", "fire hydrant", "cat", "dog",
]
Esa lista no es fija: puedes agregar las clases que quieras o cargar un modelo entrenado por ti. Tres reglas adicionales evitan que la persona se sature de información:
DISTANCE_LIMIT_RATIO = 0.70 # qué tan cerca debe estar para avisar
CENTER_ZONE_RATIO = 0.35 # el 35% central de la imagen = "al frente"
SPEECH_COOLDOWN = 2.5 # segundos entre avisos repetidos
El cooldown evita que el sistema repita "persona, persona, persona" mientras caminas al lado. Si después de unos segundos el objeto sigue ahí, vuelve a anunciar, lo que es útil porque indica que no se ha movido.
Traducción COCO a español
Los labels de COCO vienen en inglés. Un diccionario simple resuelve la mayoría antes de mandarlos a la voz:
ES = {
"person": "persona",
"bicycle": "bicicleta",
"car": "auto",
"motorcycle": "moto",
"bus": "bus",
"truck": "camion",
"traffic light": "semaforo",
"stop sign": "pare",
"bench": "banca",
"dog": "perro",
"cat": "gato",
"backpack": "mochila",
"chair": "silla",
"couch": "sofa",
"bed": "cama",
"tv": "televisor",
"laptop": "notebook",
"cell phone": "celular",
"book": "libro",
"scissors": "tijera",
}
def translate_to_spanish(label):
return ES.get(label, label)
Para anunciar en español, la llamada a eSpeak usa la voz es:
import subprocess
def announce(label):
subprocess.Popen(["espeak", label, "-ves", "-s", "140"])
Dirección y distancia: el truco de las dos líneas
En la prueba real, la pantalla muestra dos líneas verticales que marcan el 35% central. Solo se anuncia un objeto si el centro de su recuadro cae entre esas dos líneas, es decir, si está directamente al frente. Si aparece a la izquierda o a la derecha, el sistema lo ignora a propósito para no molestar.
def direction(bbox, img_w):
x = (bbox[0] + bbox[2]) / 2
if x < img_w / 3: return "a la izquierda"
elif x < 2 * img_w / 3: return "al frente"
else: return "a la derecha"
La distancia también filtra: si el objeto está lejos, no hay aviso. A medida que se acerca y queda al frente, recién ahí salta la voz (con una etiqueta tipo "FAR" o "NEAR" según qué tan cerca está). Así la persona puede ajustar el rumbo a tiempo. El sistema sigue funcionando con la cámara en movimiento sobre el pecho, no solo quieta sobre la mesa.
![Monitor mostrando la detección en vivo: una moto dentro de un recuadro amarillo etiquetado "motorcycle [FAR]", con la imagen dividida en tres zonas verticales](https://images.mechatronicstore.cl/articles/blog/16d08ade217e/f793385e70dd42dc.webp)
Reconocer billetes chilenos (entrenamiento propio)
COCO no incluye billetes, y la identificación de dinero es justo uno de los problemas más sentidos: sin ayuda, hay que confiar en terceros. Para los billetes de CLP 1.000, 2.000, 5.000, 10.000 y 20.000 puedes entrenar un modelo propio:
- Toma alrededor de 150 fotos por billete en distintos ángulos, luz y pliegue.
- Anótalos en una herramienta como Roboflow (clases
bill_1000,bill_2000, etc.). - Entrena un YOLO chico (por ejemplo en Google Colab).
- Convierte el modelo al formato de la BPU con la toolchain de D-Robotics.
- Cárgalo junto al modelo base:
if clase == "bill_5000": announce("Cinco mil pesos").
Solución de problemas frecuentes
Cuatro fallas típicas la primera vez que lo corres:
- La cámara está conectada pero el script no abre el video. Suele ser el índice de cámara. El código usa
cv2.VideoCapture(0)por defecto, pero con un hub USB o varias cámaras la RDK X5 puede asignar otro número. Prueba1o2, o lista los dispositivos conls /dev/video*. Los puertos USB 3.0 son más confiables que los 2.0 para streaming. - Detecta objetos pero no se escucha la voz. Casi siempre es audio. Confirma que parlantes o audífonos estén conectados y el volumen arriba (
amixer sset 'Master' 100%). Si el código usa gTTS, este necesita internet y falla en silencio sin conexión: usa un motor offline como eSpeak o pyttsx3. - Hay un retardo largo entre ver el objeto y oír el aviso. Un retraso de 3 a 5 segundos es peligroso. La causa más común es generar el audio en el mismo hilo que el loop de detección. Mueve la reproducción a un hilo aparte para que la detección no se detenga. Y baja la resolución a 640x480 o 416x416: la precisión cambia poco y la velocidad mejora mucho.
- Anuncia demasiados objetos a la vez. Demasiada información es tan inútil como ninguna. Por eso existen los filtros: anuncia solo si el centro del recuadro cae en la zona central y supera un umbral mínimo de confianza, con el cooldown entre avisos.
Variantes y mejoras
- Botón de pánico físico que dispara una llamada o mensaje a un contacto pregrabado.
- Brújula más GPS para dar dirección absoluta, por ejemplo "salida del Metro hacia el norte".
- Modo conversacional offline con un modelo de lenguaje local: la persona pregunta "¿qué hay enfrente?" y el sistema describe la escena en una frase, en vez de solo nombrar objetos sueltos.
Personalización para Chile (MechatronicStore)
La RDK X5 se importa directo desde D-Robotics o por marketplaces, no es stock común en Chile. Pero la electrónica de soporte para el armado (prototipar el botón de pánico, un LED indicador o el cableado de prueba) sí la tienes a mano:
- Protoboard 830 puntos (MB102): prototipado del botón y el LED indicador.
- Cable macho a hembra 10 cm: conexiones rápidas entre la placa y el botón o LED.
Alternativas si no quieres esperar la RDK X5:
- Raspberry Pi 5 más AI HAT: misma idea de inferencia acelerada, pero sumando la placa extra que la RDK X5 te ahorra.
- Jetson Nano usada: más antigua, pero corre un YOLO chico de forma decente.
Recursos
- Tutorial original: AI for the Visually Impaired: Real-Time Talking Object Detection, por Engr. Shahzada Fahad (Electronic Clinic).
- Código completo del proyecto: disponible en la página de Patreon del autor (carpeta
Blind_prople_project, conblind.pyyespeak_test.py). - RDK X5 (D-Robotics): developer.d-robotics.cc
- YOLOv5: github.com/ultralytics/yolov5
- eSpeak NG: github.com/espeak-ng/espeak-ng
- Dataset COCO: cocodataset.org
Versión chilena, basada en el proyecto original, con componentes de apoyo en stock local en MechatronicStore.



